时间:2021-07-01 10:21:17 帮助过:136人阅读
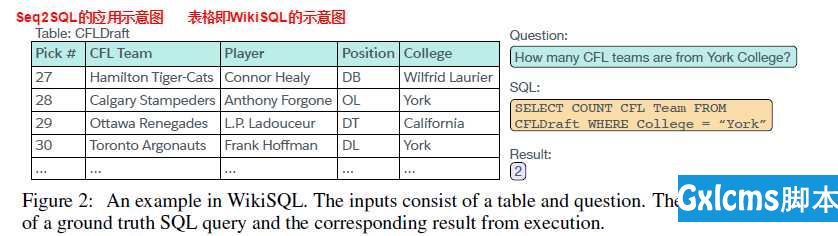 试验结果显示,Seq2SQL的准确率也不是特别的高,只有60.3%
试验结果显示,Seq2SQL的准确率也不是特别的高,只有60.3%  Seq2SQL由三部分组成:
Seq2SQL由三部分组成: 第一部分: Aggregation classifier 这一部分其实是一个分类器,将用户输入的语句分类成是select count/max/min 等统计相关的约束条件 在此处采用的Augmented Pointer Network,Augmented Pointer Network总体而言也是ecoder-to-decoder的结构, encoder采用的是两层的bi-LSTM, decoder 采用的是两层的unidirectional LSTM, encoder输出h,ht对应的是第t个词的输出状态 decoder的每一步是,输入y s-1,输出状态gs,接着,decoder为每个位置t生成一个attention的score
第一部分: Aggregation classifier 这一部分其实是一个分类器,将用户输入的语句分类成是select count/max/min 等统计相关的约束条件 在此处采用的Augmented Pointer Network,Augmented Pointer Network总体而言也是ecoder-to-decoder的结构, encoder采用的是两层的bi-LSTM, decoder 采用的是两层的unidirectional LSTM, encoder输出h,ht对应的是第t个词的输出状态 decoder的每一步是,输入y s-1,输出状态gs,接着,decoder为每个位置t生成一个attention的score 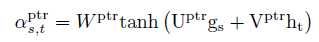 ,最终生成
,最终生成 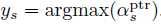 在Seq2SQL中,首先为input生成一个表征向量
在Seq2SQL中,首先为input生成一个表征向量 (agg:aggregation clasifier, inp:input,enc:encoder) 首先为Augmented Pointer Network类似,计算出一个attention的分数,
(agg:aggregation clasifier, inp:input,enc:encoder) 首先为Augmented Pointer Network类似,计算出一个attention的分数,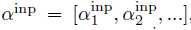 量化后,通过softmax函数
量化后,通过softmax函数 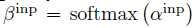 input的表征向量
input的表征向量 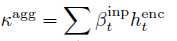 通过一个多层的网络和softmax完成分类任务
通过一个多层的网络和softmax完成分类任务 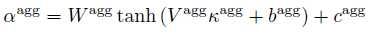 ,
, 第二部分: select column 这一部分是看用户输入的问句命中了哪个column 首先将每个column name 通过LSTM encode
第二部分: select column 这一部分是看用户输入的问句命中了哪个column 首先将每个column name 通过LSTM encode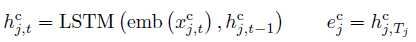 将用户输入encode成与第一部分
将用户输入encode成与第一部分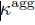 类似的
类似的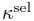 最终通过一个多层的神经元和softmax确定是命中哪一行
最终通过一个多层的神经元和softmax确定是命中哪一行 
 第三部分:where clause 确定约束条件,因为最终生成的SQL可能与标注中的不太一样,但是依旧有一样的结果,所以不能像前两部分一样使用交叉熵作为loss训练,因此使用强化训练中reward函数 (g: ground-truth), loss使用梯度
第三部分:where clause 确定约束条件,因为最终生成的SQL可能与标注中的不太一样,但是依旧有一样的结果,所以不能像前两部分一样使用交叉熵作为loss训练,因此使用强化训练中reward函数 (g: ground-truth), loss使用梯度
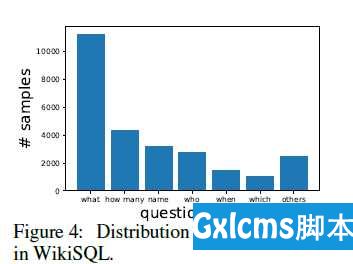

Seq2SQL :使用强化学习通过自然语言生成SQL
标签:layout enc 状态 sea 分组 语句 col dir ges