时间:2021-07-01 10:21:17 帮助过:10人阅读
SELECT vend_name, prod_name, prod_price, quantityFROM vendors, products, orderitemsWHERE vendors.vend_id = products.vend_id AND orderitems.prod_id = products.prod_id;
//INNER JOIN方式SELECTvend_name,prod_name,prod_price,quantityFROM(vendors INNER JOIN products ON vendors.vend_id = prodcuts.vend_id)INNER JOIN orderitems ON orderitems.prod_id = products.prod_id;
 所以,现在我们已经明白了,原来数据库在执行我们的SQL的时候,是会对执行顺序进行优化调整的。另外,要注意的是,这里的驱动表,并不是说数据量小的就是驱动表,我们刚才也提过,如果仅仅以表的大小来作为驱动表的判断依据,假若小表过滤后所剩下的结果集比大表多很多,结果就会在嵌套循环中带来更多的循环次数,这种情况小表驱动大表反而是低效率了。
所以,现在我们已经明白了,原来数据库在执行我们的SQL的时候,是会对执行顺序进行优化调整的。另外,要注意的是,这里的驱动表,并不是说数据量小的就是驱动表,我们刚才也提过,如果仅仅以表的大小来作为驱动表的判断依据,假若小表过滤后所剩下的结果集比大表多很多,结果就会在嵌套循环中带来更多的循环次数,这种情况小表驱动大表反而是低效率了。
EXPLAINSELECT *FROM(SELECT * from t_rank AS r JOIN csic_delegation_dict AS dele ON r.commonCode_Delegation = dele.DELEGATION_CODE) tmp1JOIN csic_event AS eve ON tmp1.commonCode_Event = eve.EVENT
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-----------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+------------+--------+-------------------+---------+---------+------+------+-----------+| 1 | PRIMARY | eve | ALL | NULL | NULL | NULL | NULL | 441 | || 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 504 |Using where|| 2 | DERIVED | dele | ALL | NULL | NULL | NULL | NULL | 41 | || 2 | DERIVED | r | ALL | NULL | NULL | NULL | NULL | 539 |Using where|+----+-------------+------------+--------+-------------------+---------+---------+------+------+-----------+
| 该字段的值 | 含义 |
| SIMPLE | 简单的SELECT,不适用UNION或子查询等 |
| PRIMARY | 查询中包含任何复杂的子部分,最外层的SELECT标记为PRIMARY |
| UNION | UNION中的第二个或后面的SELECT语句 |
| DEPENDENT UNION | UNION中的第二个或后面的SELECT语句,取决于外面的查询 |
| UNION RESULT | UNION的结果 |
| SUBQUERY | 子查询中的第一个SELECT |
| DEPENDENT SUBQUERY | 子查询中的第一个SELECT,取决于外面的查询 |
| DERIVED | 派生表的SELECT,FROM子句的子查询 |
| UNCACHEABLE SUBQUERY | 一个子查询的结果不能被缓存,必须重新评估外链接的第一行 |
mysql> EXPLAIN SELECT * FROM (SELECT * FROM ( SELECT * FROM t1 WHERE id=2602) a) b;+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | || 2 | DERIVED | <derived3> | system | NULL | NULL | NULL | NULL | 1 | || 3 | DERIVED | t1 | const | PRIMARY,idx_t1_id | PRIMARY | 4 | | 1 | |+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| 该字段的值 | 含义 |
| ALL | 遍历全表 |
| index | 与ALL的区别在于只遍历索引树 |
| range | 表示只操作单表,且符合查询条件的记录不止1条 |
| ref | 表明本步执行计划操作的数据集中关联字段是索引字段,但不止1条记录符合上步执行计划操作的数据集的关联条件 |
| eq_ref | 表明本步执行计划操作的数据集中关联字段是索引字段,且只有1条记录符合上步执行计划操作的数据集的关联条件 |
| const | 表明上述"table"字段代表的数据集中,最多只有1行记录命中本步执行计划的查询条件 |
| system | system只是const值的一个特例,它表示本步执行计划要操作的数据集中只有1行记录 |
| 该字段的值 | 含义 |
| Using index | 表示使用索引,如果只有 Using index,说明他没有查询到数据表,只用索引表就完成了这个查询,这个叫覆盖索引。如果同时出现Using where,代表使用索引来查找读取记录, 也是可以用到索引的,但是需要查询到数据表。 |
| Using where | 表示条件查询,如果不读取表的所有数据,或不是仅仅通过索引就可以获取所有需要的数据,则会出现 Using where。如果type列是ALL或index,而没有出现该信息,则你有可能在执行错误的查询:返回所有数据。 |
| Using filesort | 不是“使用文件索引”的含义!filesort是MySQL所实现的一种排序策略,通常在使用到排序语句ORDER BY的时候,会出现该信息。 |
| Using temporary | 表示为了得到结果,使用了临时表,这通常是出现在多表联合查询,结果排序的场合。 |
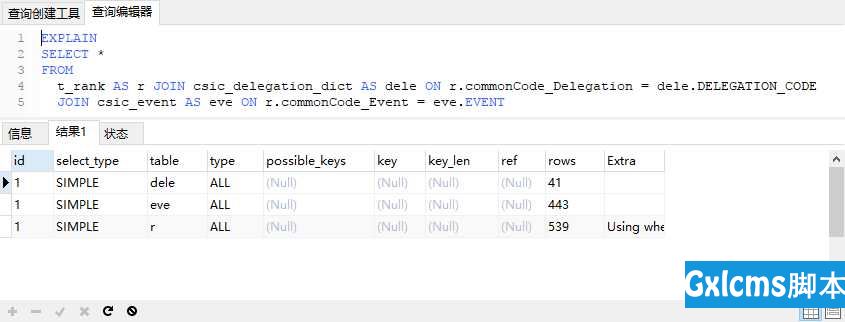 SQL查询时间为9s:
SQL查询时间为9s: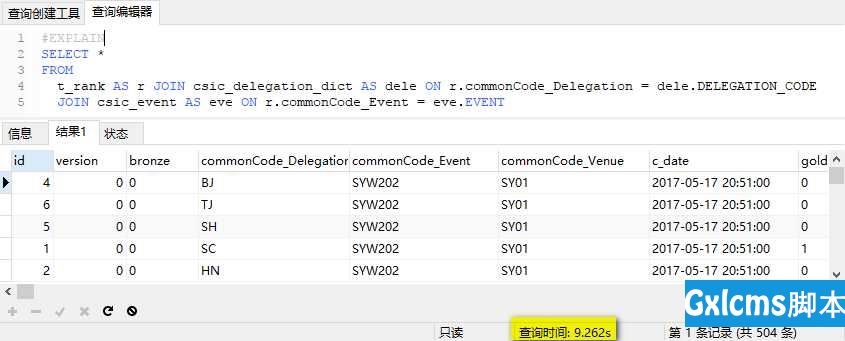
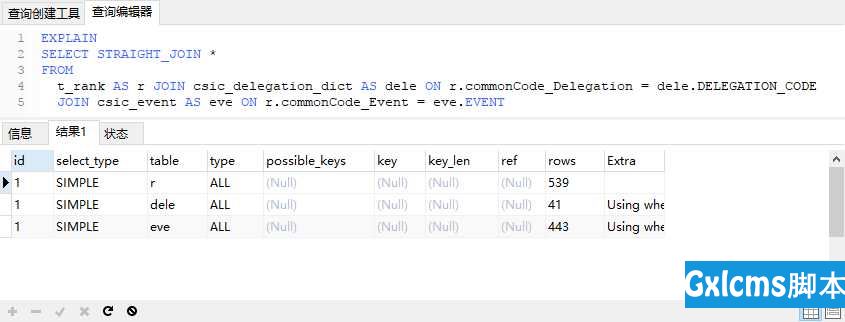 SQL查询时间为0.2s:
SQL查询时间为0.2s: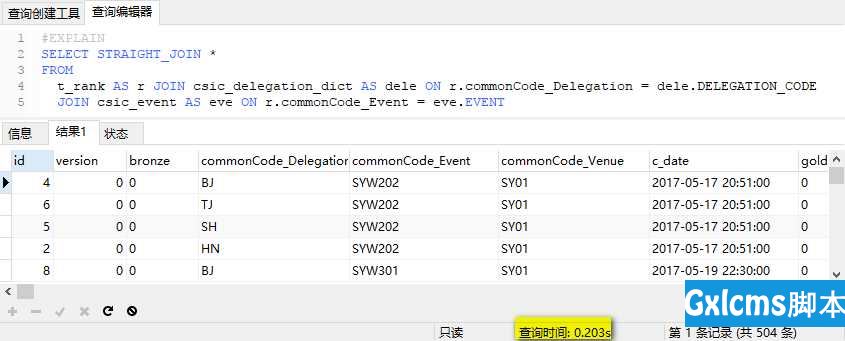 但是仍然需要引起注意的是,这种方式因为执行顺序被固化了,那么随着时间的推移,数据库中的数据分布随着业务开展而发生变化,很可能导致原本运行顺畅的SQL逐渐变得糟糕。
但是仍然需要引起注意的是,这种方式因为执行顺序被固化了,那么随着时间的推移,数据库中的数据分布随着业务开展而发生变化,很可能导致原本运行顺畅的SQL逐渐变得糟糕。 浅谈SQL优化入门:2、等值连接和EXPLAIN(MySQL)
标签:and slow 算法 深度 tail 技术分享 保存 匹配 连接